On the S-Box of Streebog and Kuznyechik
Table of Contents
In late 2017, I obtained new results [1] about the S-box used by both Russian standards in symmetric cryptography, namely the block cipher (Kuznyechik) and the hash function (Streebog). They are both GOST standards and RFCs, (respectively RFC 6986 and RFC 7801). In this page, I summarize these latest results using an FAQ. I encourage the interested reader to have a look at the actual research paper, which is available online (without any paywall!) on the ToSC website.
1 General Context
1.1 What is symmetric cryptography?
Cryptography is the science dealing with information security: how can we communicate in such a way that an eavesdropper cannot spy on us? As communications are done via computers, the techniques enabling such protections are algorithms that prevent attackers from accessing the information without using a key: unless the key is known, it is impossible to read/modify the data. When the same key is used to process the information before sending and after receiving, we talk about symmetric cryptography.
It is necessary to continuously analyse these algorithms as they may eventually turn out to have flaws. This threat is not theoretical as cryptographic algorithms have failed in this way in the past. To take a recent example, the hash function SHA-1 was found to yield collisions, a critical failure for such an algorithm [4].
1.2 How are the cryptographic algorithms that we use chosen?
The algorithms that are used are usually those that have been standardized by some standardizing body (e.g. the American NIST, ISO/IEC, etc.). Each standardizing body has its own internal process for choosing ciphers.
This process can be completely opaque as evidenced by the standardization of the DUALEC PRNG by the American NIST. This algorithm turned out to have been imposed by the NSA and to likely contain a backdoor, as detailed in [8]. In this case, the algorithm was standardized basically because the NSA said it had to be. This is not a unique instance: the Russian algorithms discussed on this page were also designed secretly and then standardized without any competition or other forms of transparency. It is obviously very difficult to trust algorithms standardized in this fashion: where is the third party analysis? Where are the designers' explanations?
In order to foster trust, a much better strategy consists in organizing open competitions. For instance the AES and hash function NIST competitions yielded the standardization of algorithms that are now well trusted. This trust comes from the analysis received by these algorithms before they were standardized and from the quality of the theoretical frameworks used to construct them, frameworks which were carefully explained by their designers.
The AES, SHA-3 and the DUAL_ EC algorithms were all standardized by the same institution (the NIST), suggesting that assessing the quality of a standard is not as simple as looking at its origin.
1.3 What Are Streebog and Kuznyechik?
Streebog is a cryptographic hash function. It was standardized by the Russian Federation in 2012. Kuznyechik is a block cipher which was standardized by the same country in 2015.
Both are intended to be used in Russia. At the time of this writing, their authors are also pushing for their standardization by ISO/IEC.
1.4 What is an S-Box?
One of the basic building block to construct symmetric algorithms is the block cipher. For example the AES, one of the most widely used and well studied symmetric cryptographic algorithms, is a block cipher. So is Kuznyechik. It is also common to use a block cipher to construct a hash function using a block cipher: it is the case of SHA-2, a very common hash function, and of Streebog.
Block ciphers are built by iterating a so-called round function whose goal is to provide a weak version of the properties that the block cipher is expected to fulfil. By iterating these rounds, the properties of their composition gets stronger, and after sufficiently many rounds it provides these properties in full. A key property is non-linearity. In practice, it is usually provided by a small component called S(ubstitution)-box. An S-box is a function operating on a small enough input that its output can be specified by its lookup table. The round function then contains the parallel application of said S-box over the whole state.
The Russian algorithms both use the same S-box, π. It is specified via its lookup table (Figure 1).

Figure 1: The lookup table of \(\pi\) as it appears in its specification [3]. This function maps 0 to 252, 1 to 238, …, and 255 to 182.
The cryptographic properties of the S-box play a crucial role in the security of the algorithm because they are the only source of non-linearity. They are also at the center of the security arguments given by algorithm designers. In fact, designers are expected to explain how the S-box they used was designed and why they chose the structure their S-box has. For example, the AES has an S-box which is based on the multiplicative inverse in the finite field \(\mathrm{GF}(2^8)\). This choice is motivated by the fact that both the linearity and the differential uniformity 1 of this permutation are the lowest known to be possible.
1.5 Why is it important that we know how an S-box was made?
While the multiplicative inverse, and in fact the very S-box of the AES, are popular choices for constructing 8-bit S-boxes, they are not the only possiblity. I made a survey of the literature and compiled a list of all the 8-bit S-boxes I could get my hands on2 during my PhD [2]. They are sorted by structure in Figure 2. As we can see, the structures used vary a lot, from clear mathematical description to block cipher-like structures. These differences correspond to different goals. While it is necessary to have good cryptographic properties, it is also essential that the S-box be easy to implement for example in hardware. Depending on the priority of these constraints, the designers will use different structures.
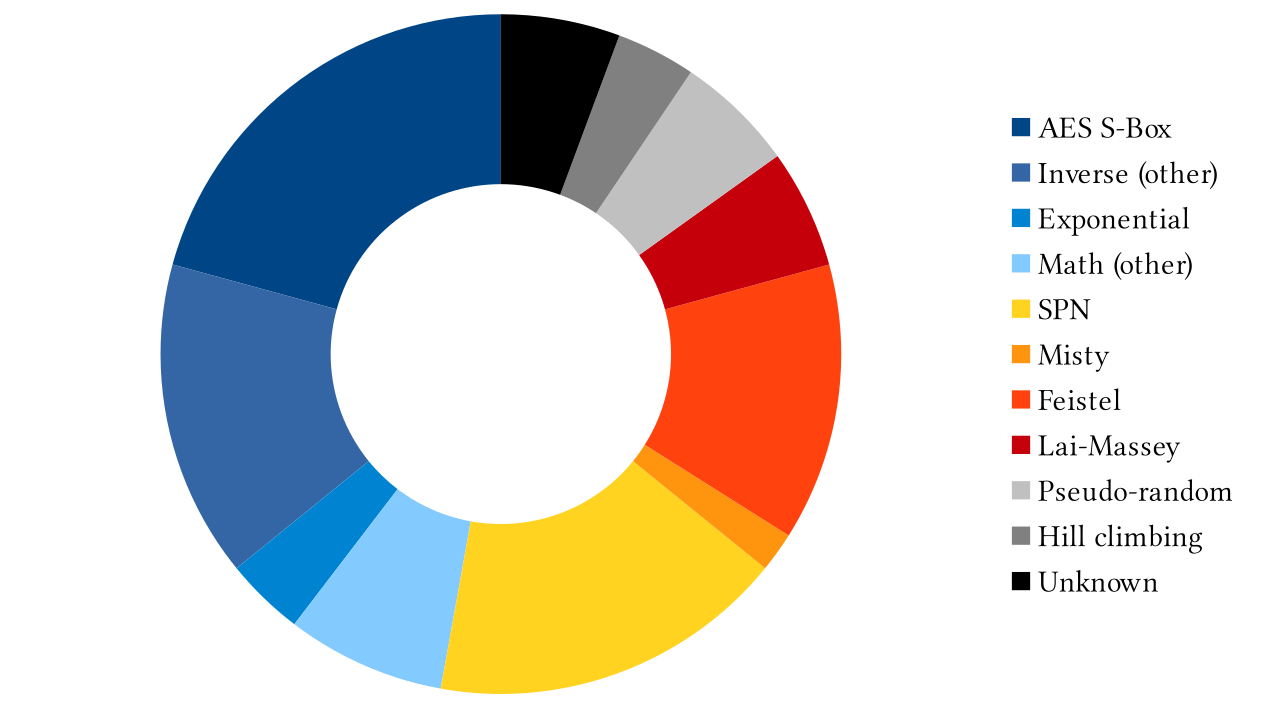
Figure 2: A survey of the structures to build the 8-bit S-boxes appearing in more than 50 different symmetric algorithms (from my PhD [2]).
In order to benefit from the easy implementation allowed by a given structure, it is necessary that the structure be public. More importantly, in order for cryptographers to be able to analyse the cipher properly, it is necessary that they are given all the information available and in particular the structure used to construct the S-box. It could be that the S-box interacts in an undesirable way with other components of the cipher and this interaction can only be noticed if the structure is known.
To see an example of the kind of constraints and trade-offs that naturally occur when designing an S-box, you can have a look at at this e-mail sent to the CFRG mailing list by one of the designers of the Belarussian standard, BelT. He explains why they decided to choose an S-box based on a discrete exponentiation—a choice I personally see nothing wrong with.
2 My Latest Result: the TKlog Structure of π
2.1 What is the structure of π?
The authors of Streebog and Kuznyechik have provided little to no information about their design process. Several cryptographers have tried to ask them about the structure of their S-box during conferences. The usual answer was equivalent to saying that they were picked at random from some set. They also claim to have lost the generation algorithm. Given the importance of the S-box, this loss should be worrying in and of itself.
With my co-authors Aleksei Udovenko and Alex Biryukov, we first identified two different decompositions of π which were published at two peer-reviewed venues: the conference EUROCRYPT'16 for the first [6] and the IACR Transactions on Symmetric Cryptology for the second [7]. However, below, I will mostly talk about the third decomposition which has been published3 in a later edition of the IACR Transactions on Symmetric Cryptology [1]. It is based on a structure which I called TKlog.
2.1.1 The TKlog
The TKlog, which I named after the TK26 (Technical Committee 26, the designers of the Russian algorithms), is a special family of permutations of which \(\pi\) is a member. These are defined by composing a discrete logarithm (mapping finite field elements to integers) with a strange but simple permutation mapping the integers back to finite field elements.
My claim that π has a TKlog structure is not up for debate: the
unconvinced reader can simply run the small SAGE script below and see
that it does indeed generate the right lookup table. It also shows the
general TKlog structure: simply change cstt, lambda_vectors or
s to generate another TKlog instance4
#!/usr/bin/sage from sage.all import * # arithmetic machinery N = 8 X = GF(2).polynomial_ring().gen() F = GF(2**8, name="a", modulus=X**8+X**4+X**3+X**2+1) alpha = F.gen() xor = lambda x,y : Integer(x).__xor__(Integer(y)) # arbitrary components s = [0, 12, 9, 8, 7, 4, 14, 6, 5, 10, 2, 11, 1, 3, 13] lambda_vectors = [0x12, 0x26, 0x24, 0x30] cstt = 0xFC # subfunction def kappa(x): result = 0 for j in xrange(0, 4): if (x >> j) & 1 == 1: result = xor(result, lambda_vectors[j]) return xor(result, cstt) # generating pi # -- pi[0] pi = [kappa(0)] # -- pi[x] for x > 0 for x in xrange(1, 2**N): l = int(F.fetch_int(x)._log_repr()) i, j = l % 17, floor(l / 17) if i == 0: y = kappa(16-j) else: gf_elmt = (alpha**17)**s[j] y = xor(kappa(16-i), gf_elmt.integer_representation()) pi.append(y) print pi
2.1.2 How can there be multiple different decompositions in π?
In this context, a decomposition is simply an algorithm that, when input \(x\), will return \(\pi(x)\). This algorithm has a priori no reason to be unique. For example, the function \(x \mapsto 4x^2\) defined over the integers, can be written as the composition of \(x \mapsto x^2\) and \(x \mapsto 4x\) or as the composition of \(x \mapsto 2x\) and \(x \mapsto x^2\). In the case of \(\pi\), it is much, much, much more complicated, but at its core the situation is the same: there are multiple ways of computing it that all yield the same result.
2.1.3 Why would the third one be "correct"?
Good question: since there are multiple ways of computing this function, why would the TKlog be the one originally intended by its designers?
This third decomposition is by far the simplest in terms of mathematics: it is completely described by a simple system of three equations, unlike the others. It also requires the fewest "arbitrary" constants; in fact, there are only about \(2^{82.6}\) different TKlog instances operating on 8 bits. This number is astonishingly small compared to the total number of 8-bit permutations, namely \(256! \approx 2^{1684}\). Hence, the probability for a random 8-bit permutation to be a TKlog is around \(2^{82.6-1684} \approx 2^{-1601}\).
Let's put this number into perspective. The probability of winning the French lottery5 is around \(2^{-24.2}\). Thus, the probability of obtaining a TKlog by picking an 8-bit permutation at random is comparable to the probability of winning the French lottery 66 times in a row!
If someone were to win this lottery 66 times in a row, would you conclude that they are astonishingly lucky or that some shenanigans were involved when picking the "random" numbers? The latter is the natural conclusion. Using the same reasoning, I claim that the presence of this structure in \(\pi\) is intentional.
2.1.4 Isn't this somewhat coherent with their claims?
One of the only claims made by the designers of these algorithms is that they picked their S-box at random from some set of S-boxes. If they picked the parameters of the TKlog randomly, wouldn't their design technically match this description?
In my opinion, no.
Suppose that someone tells you that they are going to choose 5 numbers between \(0\) and \(1,000,000\) randomly. To your surprise, they chose \(5, 2,4,5\) and \(3\). When confronting them about the obvious pattern in their result, they tell you that they used 6-sided dice rolls (i.e., a random process) to generate these numbers and that they are indeed between \(0\) and \(1,000,000\). In this case, your friend left out so much information about their process that the little given was essentially meaningless, if not misleading.
Furthermore, the authors of Streebog have argued in informal discussions (see a summary in [9]) that they wanted to avoid having too strong an algebraic structure in order to prevent some attacks. While there is nothing wrong with this approach a priori, it is completely at odds with their final result: as shown in the next section, their S-box has an extremely strong algebraic structure.
2.2 What specific properties does it have?
Any function operating on \(n\) bits can be written as a function over a finite field \(\mathbb{F}_{2^n}\). The exact correspondence between the finite field elements and their binary representation is not unique; it is determined by a specific polynomial. In the case of \(\pi\), this field is \(\mathbb{F}_{2^8}\). It contains, as a subset, the finite field \(\mathbb{F}_{2^4}\). As these sets are fields, we can define an addition (which here corresponds to a XOR, denoted "\(\oplus\)") and a multiplication6 (denoted "\(\odot\)").
The S-box \(\pi\) (as well as all TKlogs) maps the subset \(\{ a \odot x, x \in \mathbb{F}_{2^4}^* \}\) of \(\mathbb{F}_{2^8}\) to a subset of the form \(\{ b \oplus x, x \in \mathbb{F}_{2^4}^* \}\). This phenomenon is summarized in Figure 3. This means that \(\pi\) maps a simple partition of its input to a simple partition of its output.
Even worse, all \(x \in \mathbb{F}_{2^8}\) can be written7 as \(a \odot b\) with \(b \in \mathbb{F}_{2^4}\) and we then have that if \(a \neq 1\) then \(\pi(a \odot b) = f(a) \oplus g(b)\) for some functions \(f\) and \(g\). In other words, the output can divided into two halves, each of which depends only on one half of the input. However, in the input, the definition of these halves is not linear. As an other consequence, the way \(\pi\) acts on each subset \(\{ a \odot x, x \in \mathbb{F}_{2^4}^* \}\) of \(\mathbb{F}_{2^8}\) for \(a \neq 1\) is always the same. Note also that \(g\) is a permutation of \(\mathbb{F}_{2^4}\), meaning that its output is also in this subset.
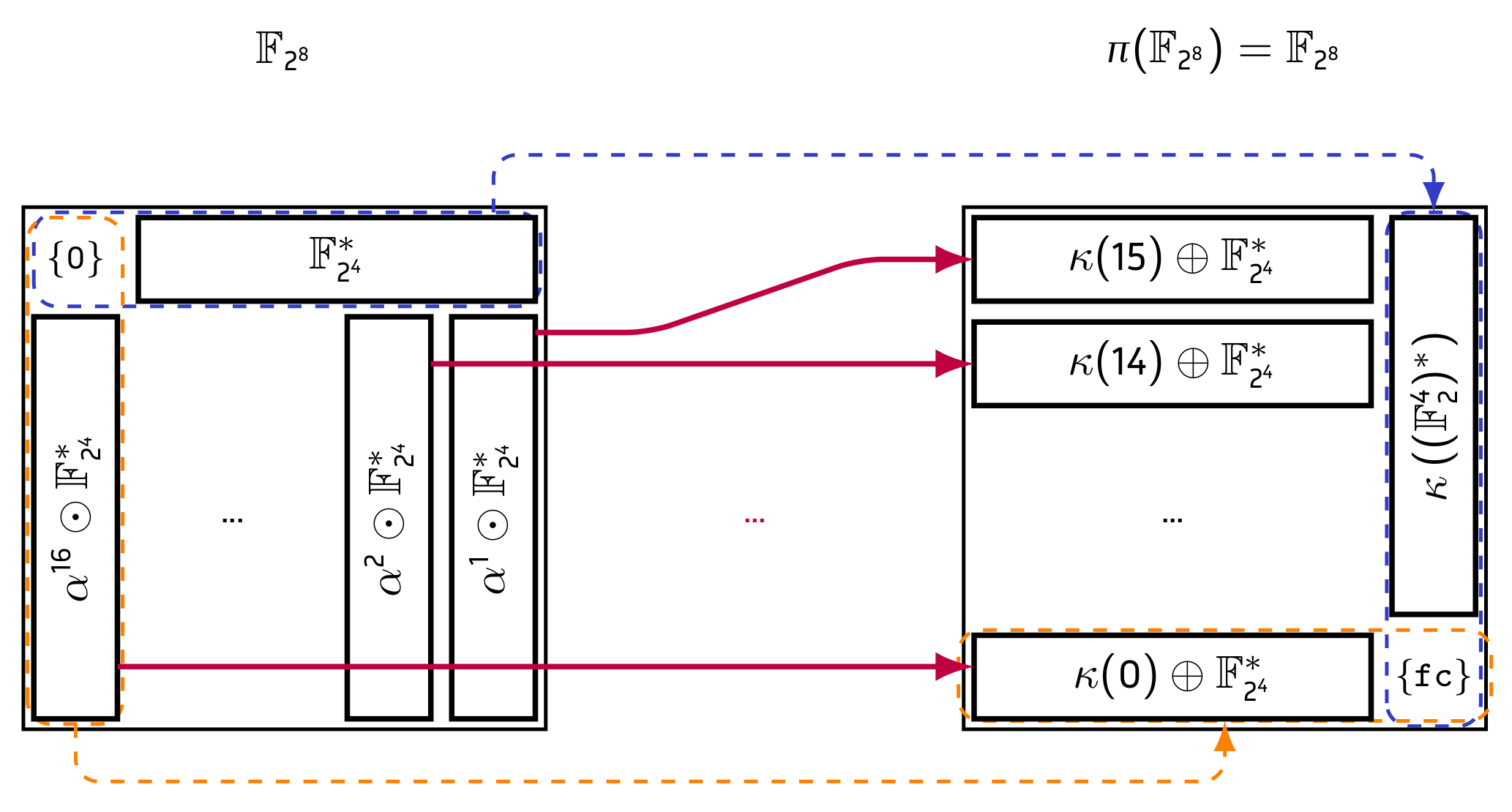
Figure 3: The main property of \(\pi\): it maps a simple partition of its input to a simple partition of its output.
2.3 Why is this worrying?
First of all, that is very strong algebraic structure where they previously claimed that there was none.
Second, Arnaud Bannier established in his PhD thesis [10] that, in order to construct a block cipher with a backdoor of a certain type, it was necessary to construct an S-box mapping sets of the form \(\{ b \oplus x, x \in V \}\) to ones of the form \(\{ b \oplus x, x \in W \}\), where \(V\) and \(W\) are vector subspaces of \(\mathbb{F}_{2^n}\) (for instance, \(\mathbb{F}_{2^4}\) is a vector subspace of \(\mathbb{F}_{2^8}\)).
That is not quite the situation we have here as \(\pi\) has such a partition in its output but not in its input. However, in the case of Streebog, the linear layer interacts in a weird way (which we have yet to completely understand) with sets of both shapes, i.e. \(\{ b \oplus x, x \in \mathbb{F}_{2^4} \}\) and \(\{ b \odot x, x \in \mathbb{F}_{2^4} \}\).
By the way, this linear layer was originally specified as a \(64 \times 64\) binary matrix, i.e. using only 0 and 1, while it is simply described by an \(8 \times 8\) matrix with elements in \(\mathbb{F}_{2^8}\). It is strange that this structure was not disclosed by the designers, especially considering that it is a natural choice: such matrices defined over \(\mathbb{F}_{2^8}\) are common in symmetric cryptography; the AES itself uses one. Why then keep it secret?
Incidentally, the design process of this matrix is also unknown. Reverse-engineering it is an open problem!
2.4 So… is it a backdoor?
First of all, I would like to emphasize that I have not found an attack leveraging these properties.
Still, I don't know the answer to the question above and, to put it bluntly, I don't think we need to know. What I think matters is whether or not this structure can lead to attacks against these algorithms. As explained in the answer to the previous question, it is a possibility. If it is indeed an exploitable flaw, why and how it ended up in these ciphers is their designers' problem, not the users'. The generation process of their S-box may have been compromised by someone else for all we know—which highlights the main issue behind these algorithms: while I have recovered the structure that was used to generate this component…
… we don't even know for sure who designed it or what their purpose was when they did!
That is why I recommend that, until their designers provide a detailed explanation of their complete design process, you do not use these algorithms and, should you be in a position to make such a decision, that you do not standardize them.
3 Updates
- 22 May 2019
- Since the publication of [1], the designers of π have insisted that the presence of the TKlog was a mere coincidence. Their arguments are factually wrong. The paper proving it is [11] and I wrote a vulgarized explanation on this page.
- 19 February 2020
- I have met with the alleged designer of this
S-box during an ISO meeting in Paris in October 2019. He
maintained his claim of randomness—and insisted that he
unfortunately lost the program generating the S-box. Make of that
what you will.
Also, I updated the form of this note (mostly CSS stuff).
4 Acknowledgements
I thank Xavier Bonnetain for proofreading first drafts of this page. I am also very grateful to Mark Seiden for his detailed comments.
5 Bibliography
- Léo Perrin. Partitions in the S-Box of Streebog and Kuznyechik IACR Transactions on Symmetric Cryptology, 2019(1), 302–329, 2019. link to tosc.iacr.org.
- Léo Perrin. Cryptanalysis, Reverse-Engineering and Design of Symmetric Cryptographic Algorithms. PhD thesis in computer science done in the cryptoLux group from the university of Luxembourg under the supervision of Alex Biryukov. Defended in April 2017.
- TC26. Information Technology – Data Security: Block ciphers. Available on tc26.ru
- Marc Stevens, Elie Bursztein, Pierre Karpman, Ange Albertini and Yarik Markov. The first collision for full SHA-1. In Jonathan Katz, Hovav Shacham, editors, Advances in Cryptology – CRYPTO 2017, vol 10401 of Lecture Notes in Computer Science, pages 570–596. Springer, Cham, July 2017. link to shattered.io
- Alex Biryukov and Léo Perrin. On reverse-engineering S-boxes with hidden design criteria or structure. In Rosario Gennaro and Matthew J. B. Robshaw, editors, Advances in Cryptology – CRYPTO 2015, Part I, volume 9215 of Lecture Notes in Computer Science, pages 116–140. Springer, Heidelberg, August 2015. link to eprint.iacr.org.
- Alex Biryukov, Léo Perrin, and Aleksei Udovenko. Reverse-engineering the S-box of streebog, kuznyechik and STRIBOBr1. In Marc Fischlin and Jean-Sébastien Coron, editors, Advances in Cryptology – EUROCRYPT 2016, Part I, volume 9665 of Lecture Notes in Computer Science, pages 372–402. Springer, Heidelberg, May 2016. link to eprint.iacr.org.
- Léo Perrin and Aleksei Udovenko. Exponential S-boxes: a link between the S-boxes of BelT and Kuznyechik/Streebog. IACR Transactions on Symmetric Cryptology, 2016(2):99–124, 2017. link to tosc.iacr.org.
- Daniel J. Bernstein, Tanja Lange and Ruben Niederhagen. Dual EC: A Standardized Back Door. Eprint report, 2015. link to eprint.iacr.org.
- M. Saarinen and B. Brumleyo. WHIRLBOB, the Whirlpool Based Variant of STRIBOB. NordSec 2015. Available on eprint.iacr.org
- Arnaud Bannier. Combinatorial Analysis of Block Ciphers With Trapdoors. PhD thesis, ENSAM 2017. Available on docs.google.com
- Xavier Bonnetain, Léo Perrin and Shizhu Tian. Anomalies and Vector Space Search: Tools for S-Box Reverse-Engineering. link to eprint.iacr.org.
Footnotes:
The linearity and the differential uniformity are used to prove that the cipher is safe respectively from linear and differential attack. To this end, these quantities have to be as low as possible.
In fact, said collection of S-boxes was added to SAGE by Friedrich Wiemer, see the documentation of the corresponding module.
And which was selected as the best paper of the conference by its committee!
While cstt can be chosen freely, the other two cannot: s
has to be a permutation of \(\{ 0, ..., 14 \}\) and lambda_vectors
must be chosen in such a way that it spans a vector space of dimension
4 that, together with the sufield, spans the whole field.
Called "Loto", it is won if 5 different numbers in \(\{ 1,...,49 \}\) and one in \(\{ 1,...,10 \}\) are chosen correctly, an event with a probability of \(\left({49 \choose 5} \times 10 \right)^{-1} \approx 2^{-24.2}\).
The definition of the multiplication in a finite field is quite different from the multiplication over the integers. However, it shares the same properties: \(a \odot 1 = a\), \(a \odot 0 = 0\), \(a \odot (b \odot c) = (a \odot b) \odot c\), and it is possible to define a multiplicative inverse so that \(a \odot (a^{-1}) = 1\).
I am implicitely using the unique decomposition into \(a \odot b\) where \(b \in \mathbb{F}_{2^4}\) and \(a = \alpha^{17i}\) for some \(i \leq 15\).